
会议论文平台
AC会议论文平台致力于为国际学术会议组织者及参与者提供高效、稳定的全流程论文管理服务。我们支持论文提交、评审、收录和出版等环节,保障学术交流的严谨与顺畅。


















| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| ISCA: International Symposium on Computer Architecture | A类 | 2026 | 2026-06-27 |
| DAC: Design Automation Conference | A类 | 2026 | 2026-07-26 |
| IPDPS: International Parallel & Distributed Processing Symposium | B类 | 2026 | 2026-05-25 |
| ICS: International Conference on Supercomputing | B类 | 2026 | 2026-07-06 |
| HPDC: ACM Symposium on High-Performance Parallel and Distributed Computing | B类 | 2026 | 2026-07-13 |
| SPAA: ACM Symposium on Parallelism in Algorithms and Architectures | B类 | 2025 | 2026-07-28 |
| CCGRID: IEEE/ACM International Symposium on Cluster, Cloud and Grid | C类 | 2026 | 2026-05-18 |
| ETS: IEEE European Test Symposium | C类 | 2026 | 2026-05-25 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| INFOCOM: IEEE International Conference on Computer Communications | A类 | 2026 | 2026-05-18 |
| MobiCom: ACM International Conference on Mobile Computing and Networking | A类 | 2026 | 2026-11-25 |
| MobiSys: International Conference on Mobile Systems, Applications, and Services | B类 | 2026 | 2026-06-21 |
| ICC: IEEE International Conference on Communications | C类 | 2026 | 2026-05-24 |
| WoWMoM: IEEE International Symposium on a World of Wireless Mobile and Multimedia Networks | C类 | 2026 | 2026-06-16 |
| ISCC: IEEE Symposium on Computers and Communications | C类 | 2026 | 2026-06-23 |
| APNet: Asia-Pacific Workshop on Networking | C类 | 2026 | 2026-08-11 |
| MSN: International Conference on Mobility, Sensing and Networking | C类 | 2026 | 2026-12-03 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| S&P: IEEE Symposium on Security and Privacy | A类 | 2026 | 2026-05-18 |
| PKC: International Workshop on Practice and Theory in Public Key Cryptography | B类 | 2026 | 2026-05-25 |
| DSN: International Conference on Dependable Systems and Networks | B类 | 2026 | 2026-06-22 |
| ASIACCS: ACM Asia Conference on Computer and Communications Security | C类 | 2026 | 2026-06-01 |
| SEC: IFIP International Information Security and Privacy Conference | C类 | 2026 | 2026-06-09 |
| ACNS: International Conference on Applied Cryptography and Network Security | C类 | 2026 | 2026-06-22 |
| EuroS&P: IEEE European Symposium on Security and Privacy | C类 | 2026 | 2026-07-06 |
| EAI SecureComm: EAI International Conference on Security and Privacy in Communication Networks | C类 | 2026 | 2026-07-21 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| PLDI: ACM SIGPLAN conference on Programming Language Design and Implementation | A类 | 2026 | 2026-06-17 |
| ESEC/FSE: ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering | A类 | 2026 | 2026-07-05 |
| OSDI: Operating Systems Design and Implementation | A类 | 2026 | 2026-07-13 |
| OOPSLA: Conference on Object-Oriented Programming Systems, Languages, and Applications | A类 | 2026 | 2026-07-17 |
| ISSTA: The International Symposium on Software Testing and Analysis | A类 | 2026 | 2026-10-03 |
| CAiSE: International Conference on Advanced Information Systems Engineering | B类 | 2026 | 2026-06-08 |
| ECOOP: European Conference on Object-Oriented Programming | B类 | 2026 | 2026-06-29 |
| WICSA: IEEE International Conference on Software Architecture | C类 | 2026 | 2026-06-22 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| SIGMOD: ACM Conference on Management of Data | A类 | 2026 | 2026-05-31 |
| VLDB: International Conference on Very Large Data Bases | A类 | 2026 | 2026-08-31 |
| PODS: ACM SIGMOD Conference on Principles of DB Systems | B类 | 2026 | 2026-05-31 |
| ECML-PKDD: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery | B类 | 2026 | 2026-09-07 |
| WebDB: International Workshop on the Web and Databases | C类 | 2026 | 2026-06-05 |
| PAKDD: Pacific-Asia Conference on Knowledge Discovery and Data Mining | C类 | 2026 | 2026-06-09 |
| MDM: International Conference on Mobile Data Management | C类 | 2026 | 2026-06-29 |
| DEXA: International Conference on Database and Expert Systems Applications | C类 | 2026 | 2026-08-11 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| STOC: ACM Symposium on Theory of Computing | A类 | 2026 | 2026-06-22 |
| LICS: Annual ACM/IEEE Symposium on Logic in Computer Science | A类 | 2026 | 2026-07-20 |
| CAV: International Conference on Computer Aided Verification | A类 | 2026 | 2026-07-26 |
| SoCG: ACM Symposium on Computational Geometry | B类 | 2026 | 2026-06-08 |
| ICALP: International Colloquium on Automata, Languages and Programming | B类 | 2026 | 2026-07-07 |
| CCC: IEEE Conference on Computational Complexity | B类 | 2026 | 2026-08-03 |
| IPCO: Conference on Integer Programming and Combinatorial Optimization | C类 | 2026 | 2026-06-17 |
| RTA/FSCD: International Conference on Formal Structures for Computation and Deduction | C类 | 2026 | 2026-07-20 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| SIGGRAPH: ACM SIGGRAPH Annual Conference | A类 | 2026 | 2026-07-19 |
| ACM MM: ACM International Conference on Multimedia | A类 | 2026 | 2026-11-10 |
| i3D: ACM Symposium on Interactive 3D Graphics | B类 | 2026 | 2026-05-15 |
| EuroVis: Eurographics Conference on Visualization | B类 | 2026 | 2026-06-08 |
| ICMR: ACM SIGMM International Conference on Multimedia Retrieval | B类 | 2026 | 2026-06-16 |
| ICME: IEEE International Conference on Multimedia &Expo | B类 | 2026 | 2026-07-05 |
| GMP: Geometric Modeling and Processing | C类 | 2026 | 2026-05-27 |
| ICIP: International Conference on Image Processing | C类 | 2026 | 2026-09-13 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| CVPR: IEEE Conference on Computer Vision and Pattern Recognition | A类 | 2026 | 2026-06-03 |
| ACL: Annual Meeting of the Association for Computational Linguistics | A类 | 2026 | 2026-07-02 |
| AAMAS: International Joint Conference on Autonomous Agents and Multi-agent Systems | B类 | 2026 | 2026-05-25 |
| ICRA: IEEE International Conference on Robotics and Automation | B类 | 2026 | 2026-06-01 |
| ICAPS: International Conference on Automated Planning and Scheduling | B类 | 2026 | 2026-06-27 |
| FG: International Conference on Automatic Face and Gesture Recognition | C类 | 2026 | 2026-05-29 |
| GECCO: Genetic and Evolutionary Computation Conference | C类 | 2026 | 2026-07-13 |
| ICPR: International Conference on Pattern Recognition | C类 | 2026 | 2026-08-17 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| UIST: Annual ACM Symposium on User Interface Software and Technology | A类 | 2026 | 2026-11-02 |
| ICWSM: The International AAAI Conference on Web and Social Media | B类 | 2026 | 2026-05-27 |
| ECSCW: European Computer Supported Cooperative Work | B类 | 2026 | 2026-06-29 |
| MobileHCI: International Conference on Human-Computer Interaction with Mobile Devices and Services | B类 | 2026 | 2026-08-31 |
| GI: Graphics Interface Conference | C类 | 2026 | 2026-06-09 |
| DIS: ACM conference on Designing Interactive Systems | C类 | 2026 | 2026-06-13 |
| UIC: International Conference on Ubiquitous Intelligence and Computing | C类 | 2026 | 2026-09-07 |
| ICMI: International Conference on Multimodal Interaction | C类 | 2026 | 2026-10-05 |
| 名称 | 类别 | 年份 | 开会日期 |
|---|---|---|---|
| RECOMB: International Conference on Research in Computational Molecular Biology | B类 | 2026 | 2026-05-26 |
| CogSci: Cognitive Science Society Annual Conference | B类 | 2026 | 2026-07-22 |
| MICCAI: International Conference on Medical Image Computing and Computer-Assisted Intervention | B类 | 2026 | 2026-10-04 |
| ICIC: International Conference on Intelligent Computing | C类 | 2026 | 2026-07-22 |
| COSIT: International Conference on Spatial Information Theory | C类 | 2026 | 2026-09-22 |
| SMC: IEEE International Conference on Systems, Man, and Cybernetics | C类 | 2026 | 2026-10-04 |
| SMC: IEEE International Conference on Systems, Man, and Cybernetics | C类 | 2025 | 2026-10-05 |
| AMIA: American Medical Informatics Association Annual Symposium | C类 | 2026 | 2026-11-07 |
















4月23日,英国泰晤士高等教育最新公布的2026年亚洲大学排名显示,清华、北大分列第一、二位。
中国内地共有97所高校上榜,其中清华大学和北京大学分别位居亚洲第一和第二;复旦大学、浙江大学、上海交通大学同样进入亚洲前十。中国科学技术大学、南京大学、哈尔滨工业大学、同济大学、武汉大学、北京师范大学均进入亚洲前三十名,共有20所高校跻身亚洲50强。
2026泰晤士中国内地大学排名

本次榜单排名前十的高校依次是:清华大学、北京大学、新加坡国立大学、新加坡南洋理工大学、东京大学、香港大学、复旦大学、浙江大学、香港中文大学、上海交通大学。
2026泰晤士亚洲大学排名百强

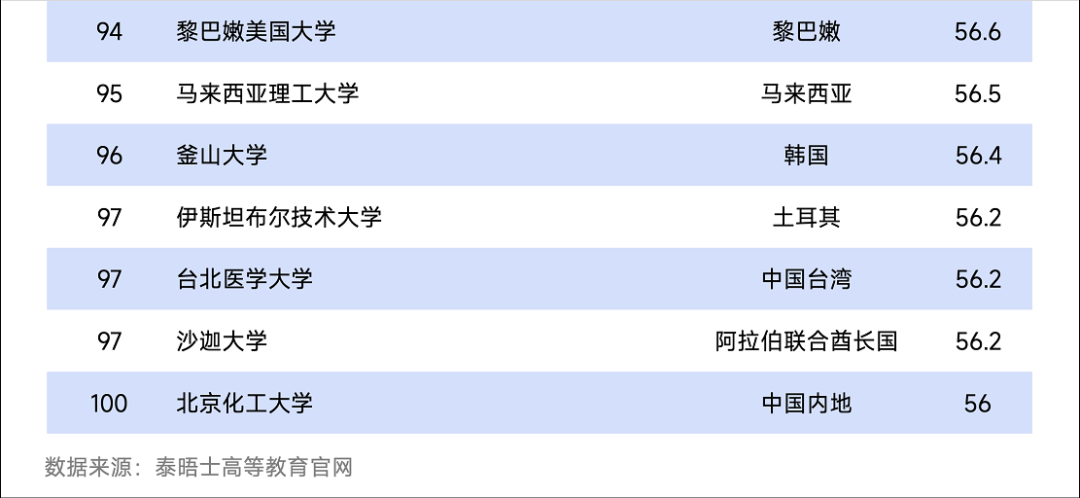
来源:泰晤士官网、青塔,仅用于学术分享,如有侵权请联系删除。

2026年4月17日至19日,第二届机器人与传感器网络国际学术会议(RoSeN 2026)在天津大学圆满召开。本次会议由天津大学主办,得到爱迩思出版社(ELSP)、ESBK国际学术交流中心、AC学术平台、贵州大学、东北大学、武汉理工大学、天津市机器人学会、澳门数字医疗与人工智能学会、天津市系统科学与工业控制学会等多所高校与科研机构的联合支持。

图1 大会现场合照
大会由天津大学左志强教授主持。会议聚焦机器人与传感器网络前沿交叉领域,围绕智能感知、自主控制、协同系统、工程应用等方向展开深入研讨,设置主旨报告与多场专题分论坛,吸引了国内外百余所高校、科研院所及企业的专家学者参会交流。

图2 主持人天津大学左志强教授
本次会议主会场邀请了四位嘉宾作主旨报告,他们分别是IEEE Fellow香港理工大学陈文华教授、国家杰出青年科学基金获得者,南开大学方勇纯教授、国家杰出青年科学基金获得者,东北大学孟凡利教授、国家杰出青年科学基金获得者,中国科学院沈阳自动化研究所刘浩教授。四位领域内顶尖专家带来了高水平学术分享,展示了机器人与传感器网络领域的最新研究成果与发展趋势。现场反响热烈,互动积极,专家与听众展开了深入的学术探讨。

图3 香港理工大学陈文华教授作主旨报告

图4 南开大学方勇纯教授作主旨报告

图5 东北大学孟凡利教授作主旨报告

图6 中国科学院沈阳自动化研究所刘浩教授作主旨报告
当日下午,大会设五个平行分会场,来自国内外高校与科研单位的学者逐一分享最新研究进展,报告内容前沿、观点鲜明、研讨充分,现场学术交流氛围浓厚,充分展现了机器人与传感器网络领域多学科交叉融合的高质量学术水准。
 |  |  |
 |  |
分论坛合照
本次会议的成功举办为专家学者们搭建了高水平、开放式、跨学科的学术交流平台,为推动机器人与传感器网络领域高质量发展汇聚了智慧和力量。

2026年4月10日至4月12日,由空间基准全国重点实验室、河南大学主办,爱迩思出版社(ELSP)、武汉大学、石河子大学、厦门理工学院数字福建自然灾害监测大数据研究所,自然资源部东南沿海海洋信息智能感知与应用重点实验室、河南省地理信息产业协会联合协办的2026国际人工智能遥感应用大会(AIRSA 2026)在河南大学(郑州校区)盛大开幕。本次会议汇聚来自人工智能与遥感应用领域的知名学者与青年才俊,围绕人工智能、大气遥感、卫星遥感、生态遥感、遥感技术应用等多个研究热点展开深入交流。

图1 大会现场合照

图2 河南大学地理科学学院执行院长赵威主持开幕式
11日上午,大会在河南大学九章学堂主会场隆重开幕。大会主席中国科学院空天信息创新研究院李正强研究员首先进行了开幕致辞,河南大学副校长白莹教授在发言中肯定了本次会议在学术交流和科技合作方面的重要作用,并对莅临现场及线上参会的国内外嘉宾表示热烈欢迎与诚挚感谢。

图3 大会主席 李正强研究员做开幕致辞图

图4 河南大学副校长白莹教授做欢迎致辞图
本次会议主会场邀请了四位嘉宾作主旨报告,他们分别是中国工程院王家耀院士、国际欧亚科学院院士、香港理工大学史文中教授、国家杰出青年科学基金获得者中国地质大学(武汉)李军教授、国家杰出青年科学基金获得者湖南大学方乐缘教授。报告涵盖人工智能、遥感应用等多个领域,展示了全球遥感领域的最新研究成果与发展趋势。现场反响热烈,互动积极,专家与听众展开了深入的学术探讨。

图5 中国工程院王家耀院士作主旨报告

图6 香港理工大学史文中教授作主旨报告

图7 中国地质大学(武汉)李军教授作主旨报告

图8 湖南大学方乐缘教授作主旨报告
会议期间举行了院长论坛,论坛由中国科学院空天信息创新研究院李正强研究员主持,香港理工大学─深圳技术创新研究院(福田)院长史文中、华北水利水电大学执行院长胡青峰、东华理工大学副院长惠振阳、河南科技学院院长李国厚、许昌学院副院长平源,围绕各学院的学科特色、人才培养亮点等开展了深入交流。

图9 院长论坛现场图
当日下午,大会设立了八个平行分会场,130场报告,围绕大气遥感、云与气溶胶偏振遥感、卫星遥感、激光雷达遥感、海洋遥感、多源遥感图像解译等领域热点方向展开多维探讨,现场学术氛围浓厚。
 |  |
 |  |
 |  |
图组 部分分会场现场合照
晚上,大会举行了颁奖典礼,颁发出最佳workshop组织奖、最佳论文、最佳学者报告等奖项,以鼓励青年学者的创新探索和卓越表现。
 |  |
图组 颁奖典礼现场
本次会议的成功举办为专家学者们搭建了高水平学术交流平台,有力促进了人工智能遥感应用领域的创新协作与成果转化,为推动相关行业高质量发展汇聚了智慧与力量。

2026年4月15日,高等教育专业评价机构软科正式发布“2026软科中国大学排名”,上榜高校共计590所。
根据主榜显示,清华大学、北京大学、浙江大学位居前三位,其他位列全国前十名的大学依次为上海交通大学、复旦大学、南京大学、中国科学技术大学、武汉大学、华中科技大学、西安交通大学。
值得关注的是,共有9所非“双一流”高校凭借强劲的综合实力跻身百强,成为榜单中的“黑马”。它们分别是:深圳大学(第66名)、浙江工业大学(第68名)、江苏大学(第81名)、南京工业大学(第88名)、福建师范大学(第90名)、浙江师范大学(第91名)、扬州大学(第93名)、广东工业大学(第96名)、杭州电子科技大学(第99名)。
2026软科中国大学排名(主榜)
* 排名或排名区间相同的大学按校名拼音顺序排列

来源:软科,仅用于学术分享,如有侵权请联系删除。
在学术论文署名时,第一作者和通讯作者是两个最受关注的角色。很多刚踏入科研领域的研究生、博士后,甚至一些青年教师,都搞不清楚:到底哪个更重要?
其实答案并不绝对——谁更重要,完全取决于你处于哪个职业阶段,以及用在什么评价场景里。
一句话说透:第一作者是研究工作的核心执行者,通讯作者是课题的总负责人。
下面从三个维度帮你彻底搞懂。
一、角色与职责完全不同
第一作者:动手干活的人
- 承担论文中最大的实际工作量
- 负责实验操作、数据采集与分析、论文初稿撰写
- 是研究成果的主要贡献者和执行者
- 署名第一作者,证明你具备独立开展科研的能力
通讯作者:拍板负责的人
- 通常是导师、教授、项目首席研究员
- 提出研究思路,把握方向,提供经费与资源
- 对论文的学术质量和真实性负最终责任
- 唯一官方联系人:负责与期刊编辑、审稿人沟通,以及发表后的学术交流
二、不同场景下,重要性截然不同
场景一:如果你是学生或求职者 → 第一作者更重要
- 对硕士、博士研究生而言,第一作者论文是毕业的硬通货,绝大多数高校明确要求。
- 找工作时,招聘方看中的是你的执行力——论文是不是你亲手做出来的。
如果你只挂了通讯作者,对方会认为那是你合作者的成果,跟你关系不大。
场景二:如果你是教授或研究员 → 通讯作者更重要
- 申请国家级基金(如国自然)、评选高级职称时,通讯作者的地位远高于第一作者。
- 通讯作者证明你是课题的总负责人,拥有独立的学术领地。
评审专家看重你是否具备领导项目的能力,而不是你还会不会亲自做实验。
一句话总结:
- 第一作者 → 证明动手能力(把活儿干好) → 科研的执行者
- 通讯作者 → 证明统筹能力(提出思想、对项目负责) → 科研的领导者
理想的学术成长路径
- 早期(博士生、博士后):力争发表高质量的第一作者论文,证明自己的科研实力。
- 中期(独立带团队后):转向发表高质量的通讯作者论文,证明自己的学术领导力。
特别提醒:共同一作怎么算?
如果论文标注了“共同第一作者”,在竞争激烈的岗位筛选时,分量通常不如唯一的第二作者?不对,原文说的是不如唯一第一作者。准确说:共同一作的地位低于唯一第一作者。也就是说,能独占第一作者尽量不与人分享。
三、学科差异也要注意
- 生物、医学、化学等实验学科:通讯作者地位很高,导师或PI作为通讯作者是常态。
- 数学、理论物理、计算机等理论学科:作者排序严格按照贡献度,第一作者被视为最主要的贡献者,通讯作者的概念相对弱化。
写在最后
第一作者和通讯作者没有绝对的“谁更重要”。
对学生,第一作者是敲门砖;对导师,通讯作者是话语权。
清楚自己当前所处的阶段,有针对性地布局署名,才能在学术道路上走得更稳、更远。
在学术论文署名中,第一作者和通讯作者是出现频率最高、争议也最大的两个角色。很多刚踏入科研领域的学生和年轻学者常常困惑:到底哪一个更重要?评职称认哪个?申基金看哪个?毕业又要求哪个?
要回答这个问题,不能简单地说“谁更重要”,因为两者的重要性体现在完全不同的维度上。下面我们从角色定义、实际贡献、学术评价体系三个角度来深度拆解。
一、角色不同:执行者 vs 负责人
- 第一作者:通常是论文具体工作的主要完成人。负责做实验、分析数据、撰写初稿、修改回复等。在多数情况下,第一作者是研究生或博士后。
- 通讯作者:是论文的总体负责人和对外联系窗口。负责提出研究思路、设计实验方案、提供经费和平台、最终审核定稿,并承担论文数据真实性和学术规范的最终责任。通常由导师、PI或团队负责人担任。
小结: 第一作者是“手脚和大脑的执行者”,通讯作者是“项目的发令人和总管家”。
二、评价体系中的权重差异:分场景来看
1. 对于学生和初级研究者:第一作者更重要
- 毕业要求:绝大多数高校和研究所要求研究生以第一作者身份发表论文才能申请学位。通讯作者通常不适用于学生。
- 求职与博士后申请:招聘单位会重点查看你作为第一作者的论文数量和质量,因为它直接证明你具备独立完成科研项目的能力。
- 青年人才项目:比如“博新计划”、“青年基金”等,也主要评价申请人的第一作者论文。
结论:如果你是学生或刚入行的青椒,拼尽全力争取第一作者,这是你的硬通货。
2. 对于导师、团队负责人:通讯作者更重要
- 职称评定:在高级职称(如副教授→教授)评审中,通讯作者通常与第一作者享有同等甚至更高的权重。很多学校明确规定,通讯作者等同于第一作者计分。
- 项目申请:国家自然科学基金等资助机构更看重申请人作为通讯作者的论文,因为这体现了独立领导团队的能力。
- 学术声望:在学术圈内,成为高水平期刊的通讯作者,意味着你是该领域的“思想源”和“责任方”,是学术领导力的象征。
结论:如果你已经独立带团队,通讯作者是你的身份标签,比第一作者更关键。
三、特殊规则:双第一作者与双通讯作者
随着跨学科合作和大实验室规模扩大,越来越多论文出现共同第一作者和共同通讯作者。
- 并列第一作者:常见于工作量巨大或需要互补技能的工作。但需要注意,排名第一的“第一位置”往往在部分单位被承认为“第一第一作者”,第二、第三位并列作者的含金量会打折扣。
- 并列通讯作者:多位资深合作者共同负责。在一些顶级期刊中司空见惯,但国内部分评审会要求标注“唯一通讯”或者更认可排在第一位的通讯作者。
提醒: 在投稿前,务必与所有合作者明确每个署名角色的含义和排序,避免后期纠纷。
四、新兴趋势与未来变化
随着开放科学(Open Science)和贡献者角色分类(CRediT)标准的普及,期刊越来越要求详细说明每位作者的具体贡献(如:策划、方法、软件、验证、写作等)。这在一定程度上稀释了“第一作者”和“通讯作者”的绝对二元地位,可能未来会转向更精细化的贡献评价体系。
但目前乃至未来5-10年,在国内学术评价体系中,第一作者和通讯作者仍是核心指标。
五、最终答案:到底哪个更重要?
没有绝对答案,取决于你的角色和阶段:
- 如果你是为了毕业或找第一份科研工作 → 第一作者更重要。
- 如果你是为了评高级职称、申请基金、确立学术地位 → 通讯作者更重要。
- 如果你两者都能拿到 → 那就是“王炸组合”,尤其当你是独立PI时,同时作为第一兼通讯作者,证明你既有一线动手能力,又有顶层设计能力。
给年轻学者的核心建议:
在读博/博后期间,全力做好第一作者,积累代表作;
独立成为导师后,尽快转向以通讯作者为主,培养自己的学生成为第一作者。
最重要的是——不要只争位置,而要真正做出扎实、创新的科学工作。好工作天然会赋予署名以价值,而非反之。
在计算机领域,CCF(中国计算机学会)推荐的国际会议与期刊分区,是衡量论文含金量的重要标尺。很多刚入门的研究生或学者常会问:A类、B类、C类投稿难度到底差多少?简单来说,A类是顶尖,B类是中坚,C类是入门。若用高考比喻:A类好比考清北,B类像是考上普通985,C类则类似冲刺一本线。下面我们从录取率、创新要求、工作量、背景影响四个维度,帮你彻底理清三个分区的真实差距。
一、录取率与投稿量
A类会议(如NeurIPS、ACM SIGKDD):全球每年投稿量高达几千甚至上万篇,最终录取仅几百篇,录取率通常在10%~20%。竞争极为惨烈,论文稍有瑕疵就会被拒。
B类会议:投稿量一般几千篇,录取率约20%~30%。虽也不容易,但拼的是扎实创新与完整实验,非必须“开天辟地”。
C类会议:投稿量几百到上千篇,录取率30%~50%甚至更高。只要工作完整、逻辑通顺、有一定新意,就有较大概率被接收,是新人试水的首选。
直观感受:A类与C类的难度差距,堪称“天壤之别”;A与B、B与C之间也各有明显分水岭。
二、创新性要求
这是三个分区最核心的区别。
A类:必须“开创性”
审稿人期待的是能改变领域走向的工作。比如提出一个全新算法,刷新多个任务的最高水平;或者发现一个此前被忽视但很重要的新问题,带火一个子方向。论文读完,审稿人会问:“这个工作会不会影响未来三五年?”
B类:需要“明显提升”
不要求颠覆,但必须比现有最好方法有明显优势。例如在现有模型上做出关键改进,效果显著提升;或者将A类的方法成功迁移到新的应用场景并解决实际难题。审稿人核心问题是:“相比当前SOTA,强在哪里?强多少?”
C类:有“新意”即可
允许小修小补。比如把别人的方法微调一下,在某个特定数据集上效果略好;或者用成熟技术解决一个具体而有价值的小问题。审稿人主要看:逻辑是否自洽,有没有明显硬伤。至于是否“重大突破”,并不强求。
三、工作量与实验
A类:实验做到“滴水不漏”
不仅要创新点牛,验证也要让所有人心服口服。通常需要:对比领域内几乎所有主流方法,在10个以上不同数据集上测试,加上详尽的消融研究、参数分析,甚至理论证明(为什么新方法有效)。结论是“不仅在多种场景下赢了,还赢得很清楚”。
B类:实验“扎实”即可
对比主要竞争对手(3~5个代表性方法),使用领域中公认的2~5个标准数据集,清晰展示优势并分析原因。不用穷尽所有可能,但要说清“怎么赢的、赢在何处”。
C类:支撑结论就够
用1~2个数据集,对比少数几个相关方法,能看出改进趋势。只要实验设计没有明显漏洞,数据真实,哪怕工作量不大,也有机会过审。
四、作者背景的隐形影响
A类:顶尖团队更有优势
审稿人大多是领域内的泰山北斗,难免对知名团队、大牛实验室的作品更关注(前提是论文质量过硬)。学生或新人若没有导师强力背书,且论文未达到“炸场级”创新,突围难度极大。
B类:相对公平,但经验有用
主要看论文本身质量。但如果你的团队已经发过几篇B类论文,会更熟悉这类会议的“口味”,中稿率比纯新人要高一些。整体上,新手经过充分准备也有机会。
C类:几乎不看背景
审稿更关注论文是否规范、实验是否完整、结论是否可靠。很多本科生、初入实验室的研究生,第一篇论文往往就从C类会议起步。这是公认的“学术练兵场”,对新人非常友好。
五、总结:如何选择适合你的分区?
| 分区 | 定位 | 录取率 | 创新要求 | 工作量要求 | 适合人群 |
|---|---|---|---|---|---|
| A类 | 顶级难度 | 10%-20% | 颠覆性、开新方向 | 极致完备 | 资深研究者、强组学生 |
| B类 | 中等偏上 | 20%-30% | 明显优于现有最好方法 | 扎实、充分 | 有经验的研究生、团队 |
| C类 | 入门级 | 30%-50%+ | 一定新意、解决小问题 | 支撑结论即可 | 本科生、初学者、快速验证 |
最后给三点实用建议:
- 新手首投选C类:先建立信心、熟悉投稿流程和审稿要求。
- 有扎实工作冲B类:若改进明显、实验完整,不妨尝试B类,性价比高。
- 冲击顶会(A类)需天时地利人和:除了创新点足够“炸”,还要有极致的实验、可能需要的学术关系(如导师知名度),并做好多次被拒的心理准备。
理解CCF分区的真实难度阶梯,才能合理制定自己的投稿策略,避免盲目踩坑或低估了A类的门槛。
在学术圈和校园文化中,我们常常会遇到这样一个有趣的语言困境:当我们习惯性地称呼男导师的妻子为“师母”时,面对女导师的丈夫,却似乎找不到一个既统一又得体的称谓。这个问题看似简单,实则涉及语言学、文化传统和社会变迁的多重维度。今天,我们就来深入探讨这个让不少人困惑的语言难题。
传统称谓的性别不对称
“师母”一词在中国传统文化中由来已久。“师”指老师,“母”则赋予其母亲般的尊崇地位,体现了“一日为师,终身为父”的传统观念,将师者之妻自然纳入家长式的尊崇体系中。然而,当导师是女性时,她的丈夫该叫什么?按照逻辑对应,似乎应该是“师公”或“师爹”,但实际使用中这些词汇要么意义已变,要么尚未被广泛接受。
有趣的是,语言学家指出,这种不对称并非汉语独有。英语中同样存在类似困境:我们习惯说“Mr. Smith”来称呼男教授的配偶,但如果教授是女性,她的丈夫却很难找到一个直接对应的尊称。这种语言现象反映了长期以来学术界以男性为主导的社会结构。
各地称呼差异:一个多元答案
实际上,不同地区和文化背景的人对此有着不同的解决方案。在台湾地区,较为通用的称呼是“师丈”。“丈”字在汉语中本就含有对成年男性的尊称意味,“师丈”自然成为女导师配偶的标准称谓。这一称呼在台湾教育体系中已被广泛接受和使用。
而在中国大陆,情况则更为多元。部分地区沿用了“师公”的说法,但“师公”在方言中又有“巫师”等其他含义,容易产生混淆。也有人使用“师爹”一词,试图与“师母”形成对仗,但“爹”字在当代语境中略显陈旧,并未得到普遍认可。
更值得关注的是,在一些较为开放的学术环境中,年轻一代学者和学生倾向于直接使用“某老师”来称呼女导师的丈夫,尤其是当对方本身也从事教育工作时。这种选择规避了称谓的尴尬,又保持了应有的尊重。
现代解决建议:因地制宜
面对这一语言学困境,现代学者和学生究竟该如何选择?我们建议采取因地制宜的策略:
首先,观察课题组或院系的惯用称呼。每个学术单位往往会形成自己的语言习惯,遵循已有惯例是最稳妥的选择。
其次,如果希望创新,可以考虑使用“某老师”这一中性且普适的称呼。在不确定的情况下,礼貌地直接询问对方希望被如何称呼,反而显得更为得体和尊重。
此外,值得注意的是,随着女性在学术界地位的提升,这一语言问题正得到更多关注。部分高校和研究机构开始倡导使用“导师的先生”或“导师的爱人”等描述性称呼,虽然略显冗长,却体现了性别平等的理念。
语言与社会变迁的思考
这一称呼困境的存在,恰恰提醒我们语言与社会结构之间的紧密关联。过去,学术界的掌舵者多为男性,“师母”一词的存在足以应对大多数情况。而今天,当越来越多女性成为学术带头人,我们的语言系统也需要相应调整以适应新的社会现实。
有趣的是,这种语言需求可能会催生新的词汇或旧词新用。“师丈”一词在大陆的使用频率正在增加,“导师先生”也开始出现在正式场合。语言本就活在人们的日常使用中,或许在不久的将来,一个被广泛接受的称呼会自然形成。
结语:尊重为本,与时俱进
在探讨女导师丈夫的称呼问题时,我们应记住,任何称谓的核心都在于表达尊重。无论是选择“师丈”、“师公”,还是简单地称呼“某老师”,真诚的态度往往比词汇本身更为重要。
这一语言困惑也提醒我们,作为社会的一部分,语言需要与时俱进,反映并尊重性别平等的社会价值观。下一次当你面临这一困惑时,不妨大胆选择一个你觉得合适的称呼,或者直接礼貌地询问对方的偏好。毕竟,打破语言困境的第一步,就是正视它的存在并主动寻求解决方案。























